
A.I
Lecture 11 : Training Neural Networks(Part 2) 본문
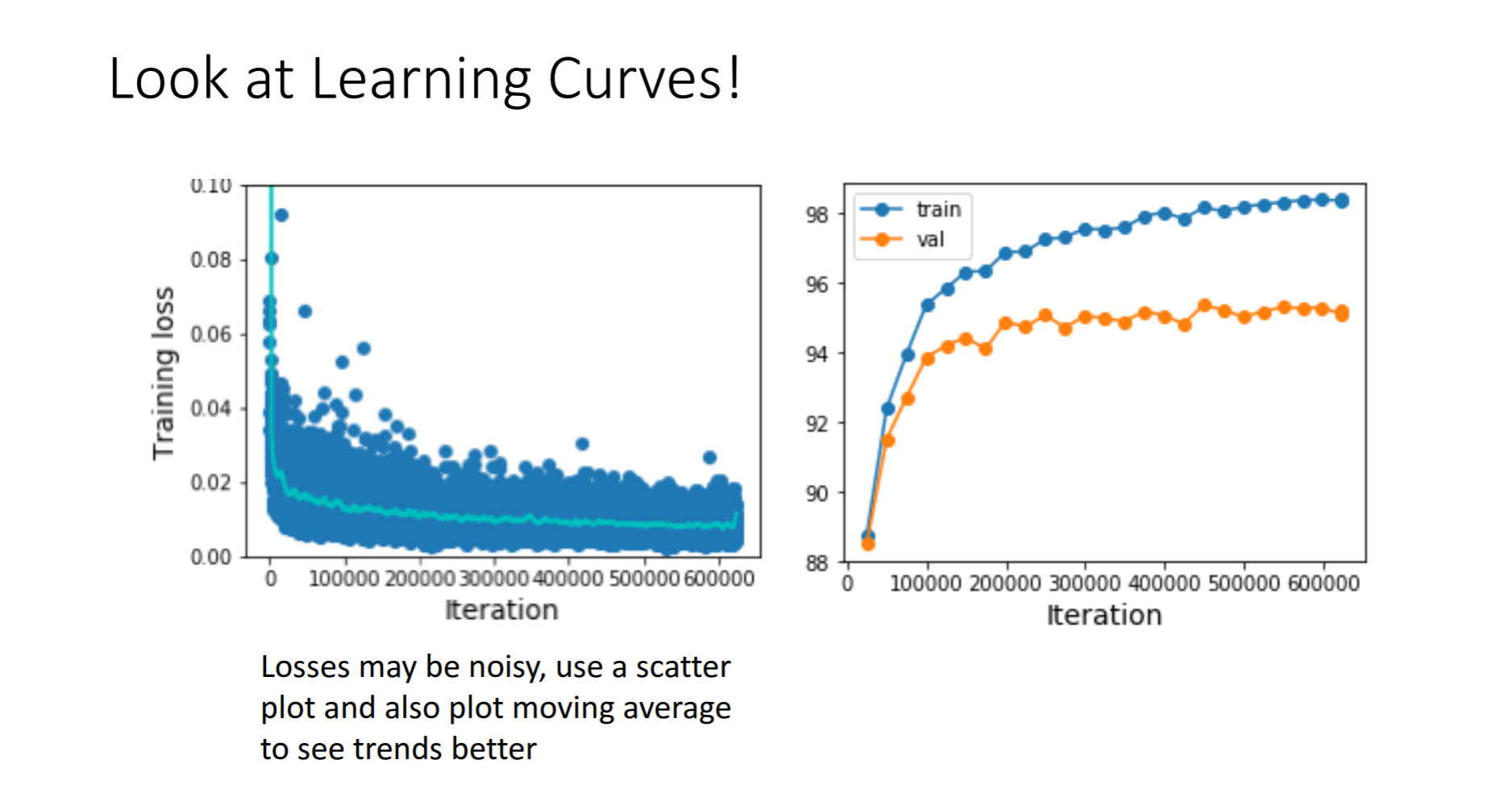
Training loss를 보면 노이즈가 많이 생성 되는 것을 볼 수 있기때문에 분산을 보여주는 플롯과 이동평균치를 구해서
트랜드를 좀더 눈에 띄게 보는 플롯을 만들 것을 권유하고있습니다.

이 Learning Curve를 보면 처음엔 평평하다가 시간이 지나는 어느 시점에 급격한 하락을 볼 수 있는데 이유는
처음에 initialization을 제대로 하지 않아서라고 합니다. 다시 처음으로 가서 initialization을 해주는 것이 해결 방법이라고 합니다.
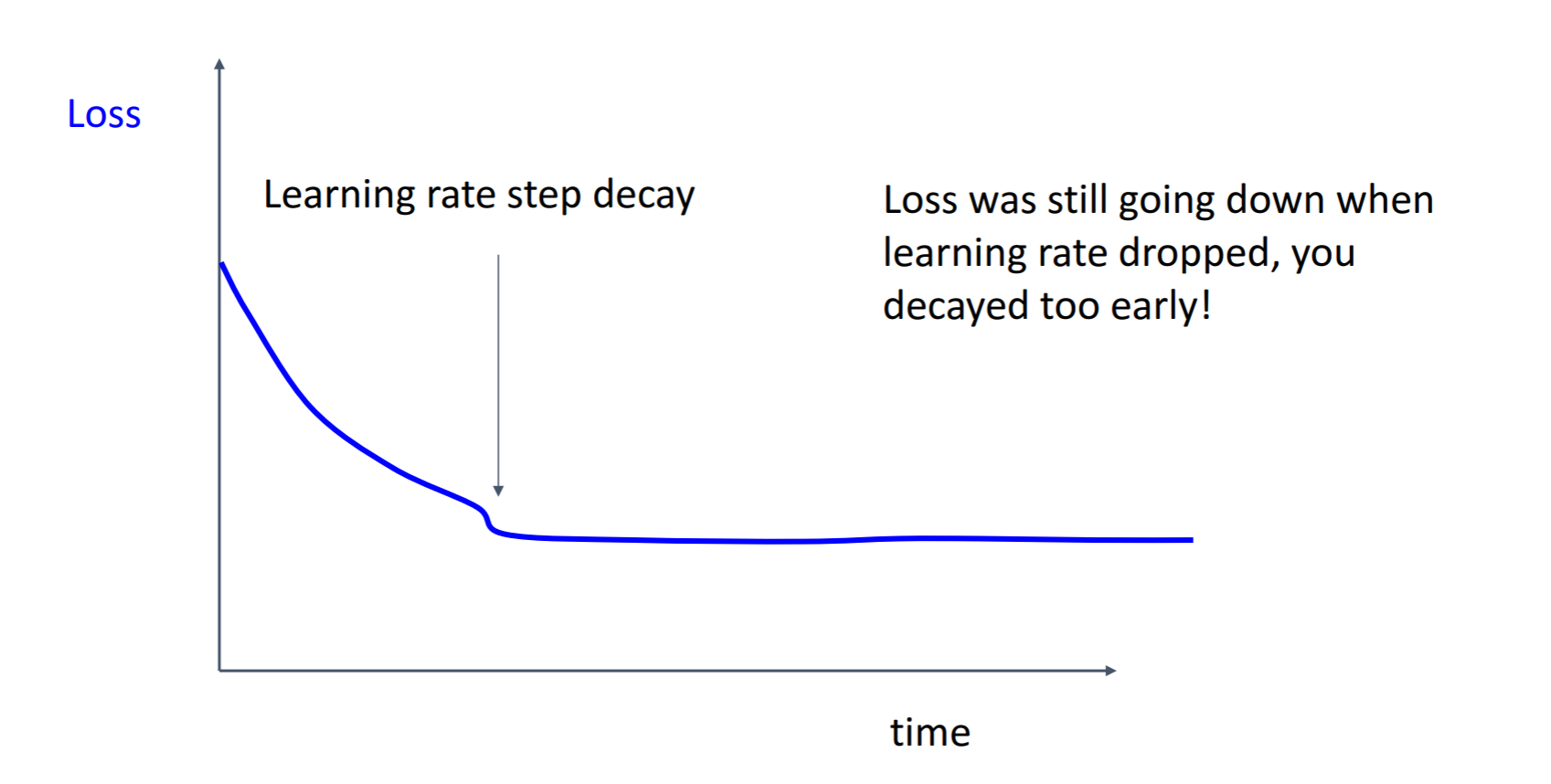
두번째로 이와 같이 처음에는 좋은 progress를 보이다가 떨어져서 평평해지는 loss curve의 형태에서 learning rate를 시작한 순간 조금의 손실이 있었고 그 이후 일정한 형상을 보이게 되는데 loss가 여전히 줄어들고 있는 상태에서 너무 일찍
학습률을 조절했기때문에 좋지 않은 형태라고 합니다.
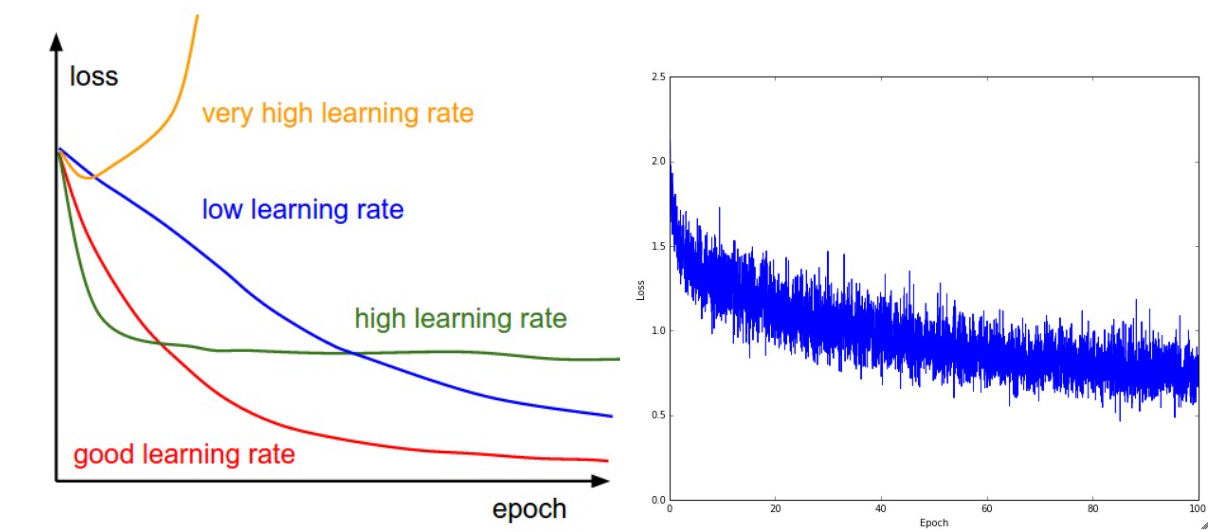
조절하지 않고 그대로 손실함수를 적용했더라면 good learning rate를 그렸을 것입니다.

다음은 Accuracy 그래프를 볼텐데, 처음에는 값이 기하급수적으로 증가하다가 어느 시점 이후 선형적으로 오르는 것을 볼 수 있습니다. 이 그래프는 훈련을 계속 할 수록 Train과 val이 계속 증가할 것이며 좋은 그래프라고 할수 있죠
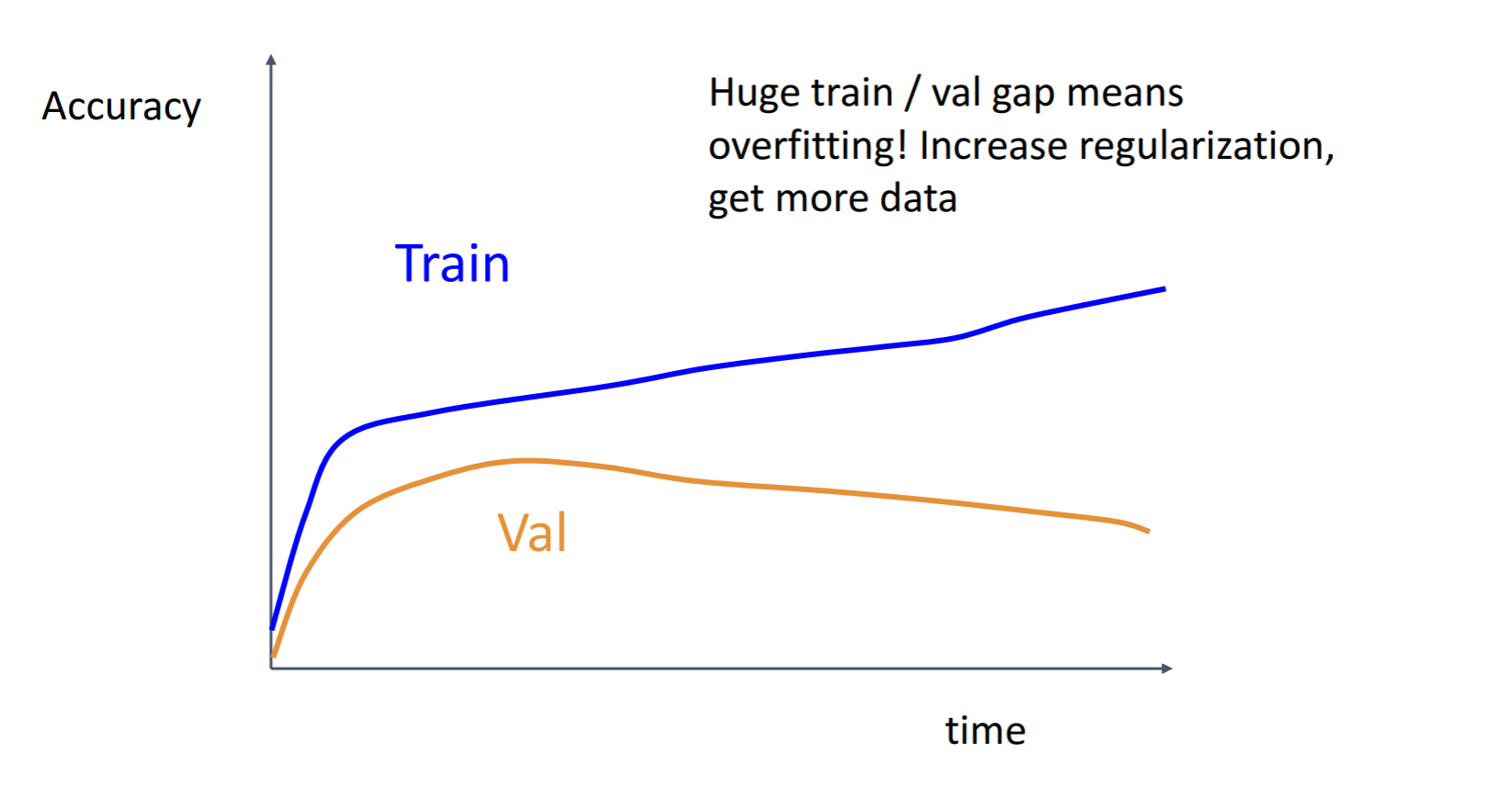
두번째 그래프는 Train값과 val 값의 Gap이 점점 커지고 있는 것을 확인할 수 있는데 과적합이 나고 있다고 볼 수 있습니다. 시간이 지남에따라 Train이 정체되거나 Val값이 점차 감소될때 나타나는 현상인데 이를 해결하기 위해서는 L2 같은 더 강한 정규화(regularization)을 쓰거나 데이터를 더 많이 모아야합니다.
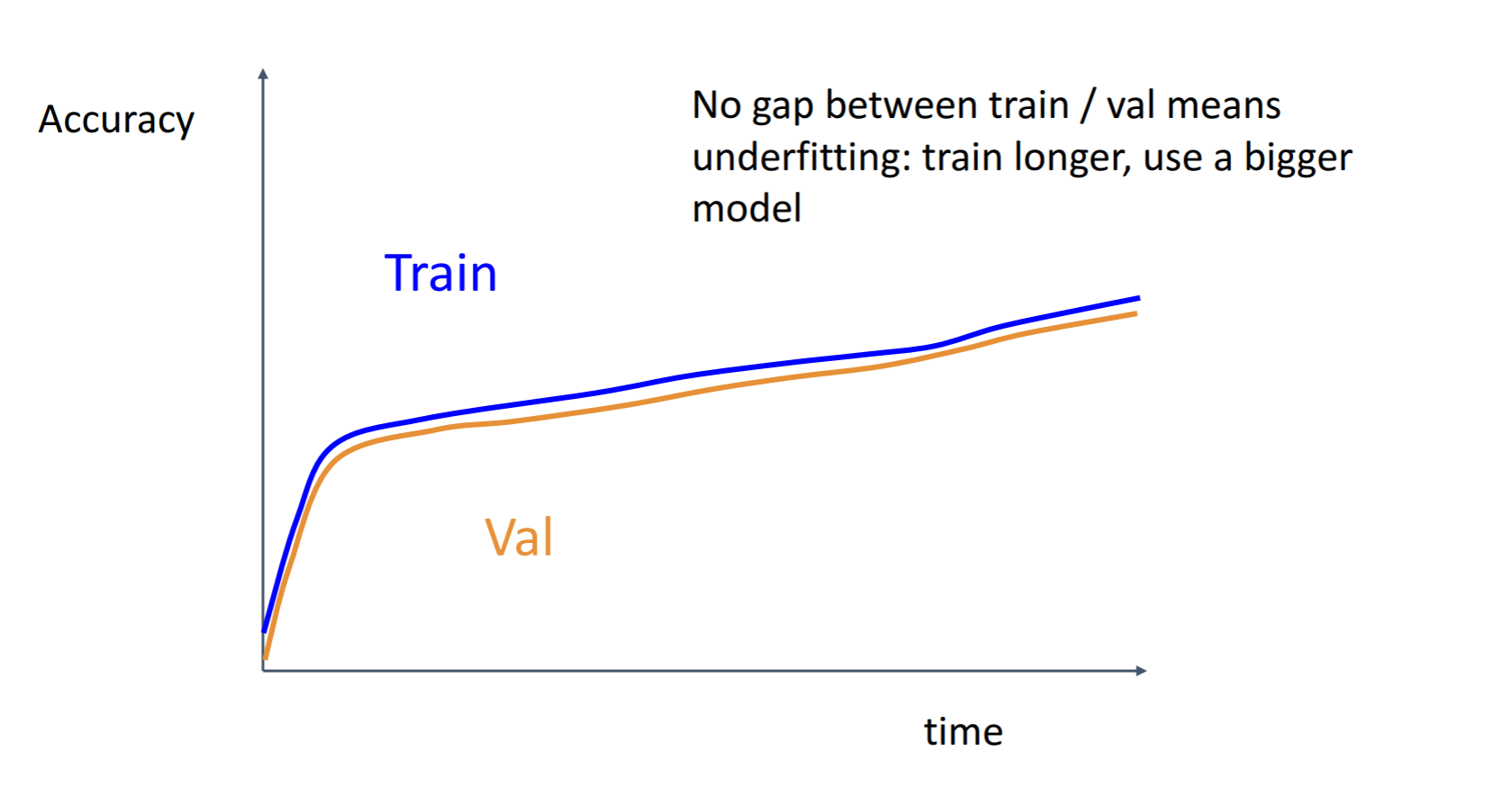
또한 이러한 Train값와 Val 값이 거의 유사하게 근접해있는 형태의 그래프도 볼 수 있습니다. 이와 같은 형태는 Underfitting이 되고있다는 뜻입니다. 모델의 수용량이 충분히 높지 않음을 이야기하는 것이며 파라미터(웨이트)의 개수를 늘려서 모델을 더 크게 만들어보는 것이 좋습니다. 강의에서는 줄여보는 것도 좋다고 합니다.

이러한 스텝을 밟아가면서 하는 것이 좋다고 하네요

그러면서 Cross-validation을 위한 command center가 있어야한다고 얘기했는데 대체적으로 요즘은 텐서보드가 그 역할을 한다고 합니다
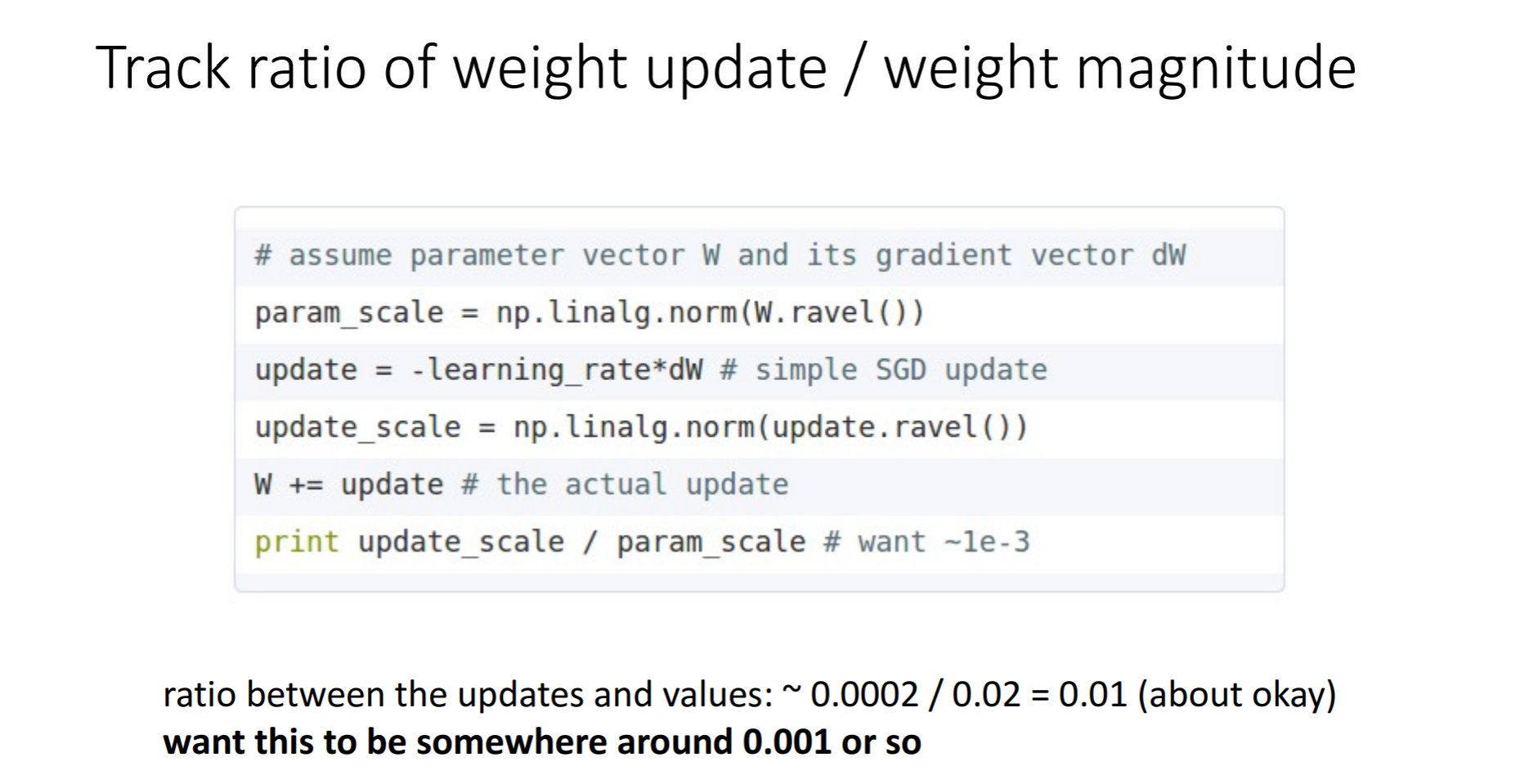
가중치의 현재 크기와 업데이트로 인한 변화량의 크기를 비교해 볼 수도 있습니다. 모든 매개 변수 세트에 대해 이 비율을 독립적으로 평가하고 추적 할 수 있습니다. 대략적인 휴리스틱은이 비율이 1e-3 정도 여야한다는 것입니다. 이보다 낮으면 학습 속도(learning rate)가 너무 낮은 것이고, 이보다 크면 학습 속도가 너무 크다고 할 수 있습니다.
최솟값이나 최댓값을 추적할 수도 있고, 그라디언트와 업데이트값의 놈(norm)을 계산하고 추적할 수도 있습니다. 이 지표들은 대개 연관성이 높아서 거의 비슷한 결과를 준다고 합니다.

그래서 학습을 다 한 후에는 무엇을 할 수 있는가에 대해 살펴보겠습니다.

그 중 하나가 자주 쓰이는 방법으로 모델 앙상블입니다.
여러 독립적인 모델로 훈련하고 샘플을 통해 각 모델들의 결과를 얻어낸 후 평균화하는 방법
이 있는데 보통 1~2%정도 성능이 좋아진다고합니다.
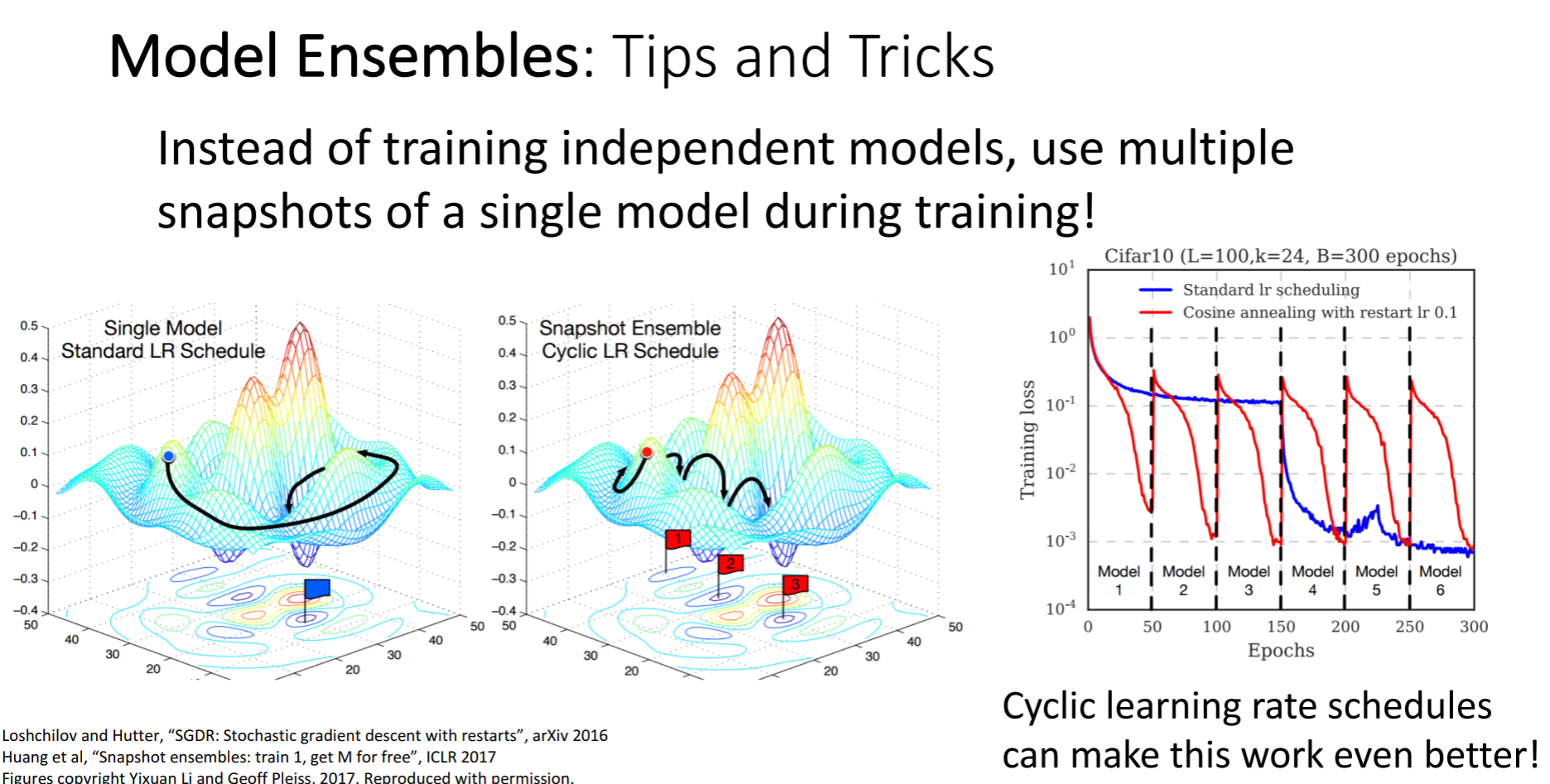
앙상블의 한 기법으로 여러 모델을 쓰기보다는 그림처럼 여러 체크포인트를 설정하여 도달하는 방법도 있다고합니다.
이와 같은 경우 learning rate를 엄청 높혔다가 낮췄다가를 반복하게 되는데 이렇게 하여 손실함수가 다양한 지역에 수렴할 수 있게 만드는 방법입니다.

실제 매개 변수 벡터를 사용하는 대신 매개 변수 벡터의 평균을 내고 테스트 시간에 사용하게 되면 결과를 좀 더 부드럽게 이끌어낼 수 있다고 합니다.

Transfer Learning이라는 개념이 등장하는데 이는 우리가 CNN으로 학습을 할 때 많은 데이터가 있어야한다는 편견을 깨게 해주었습니다.
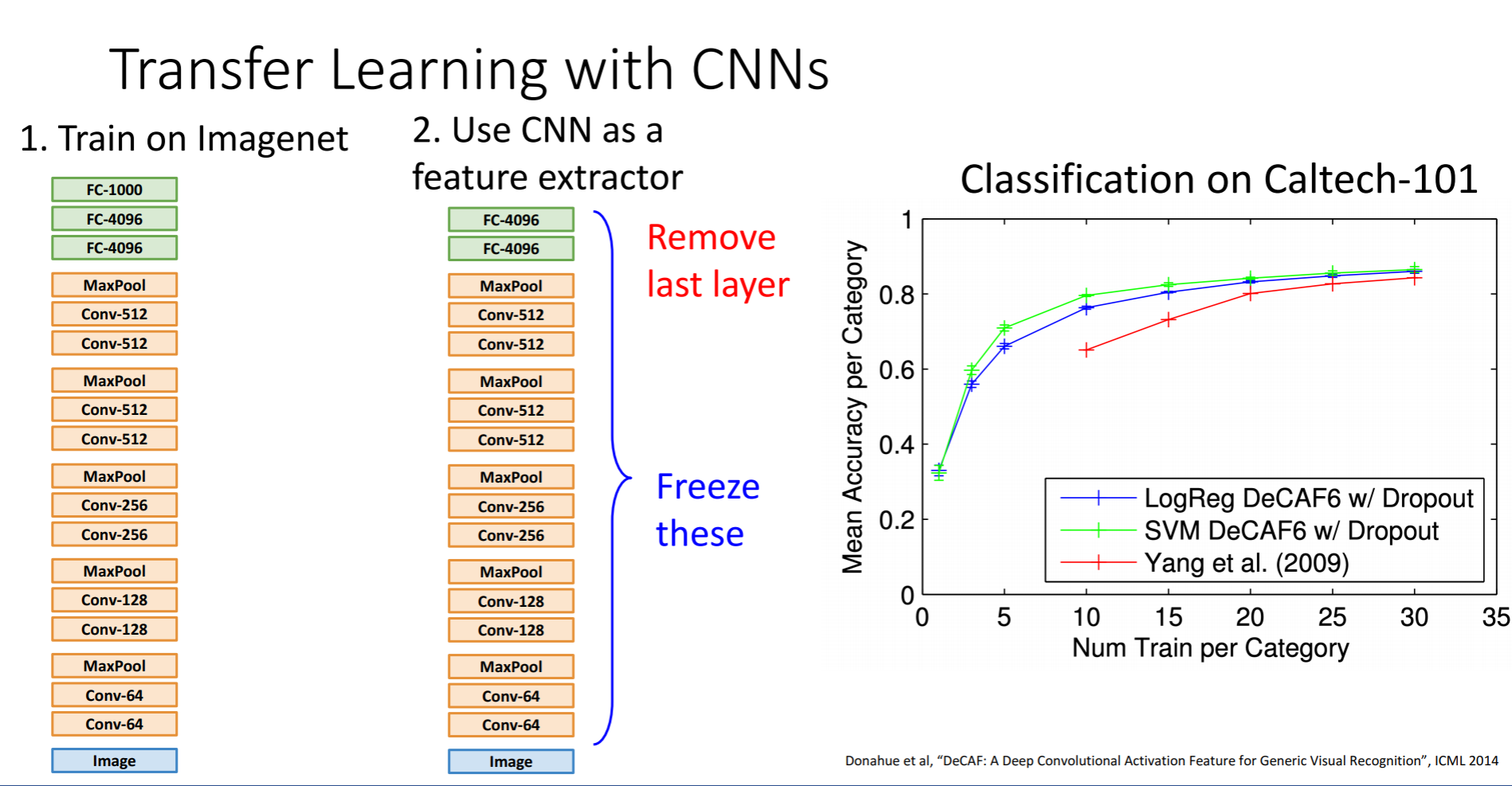
1단계로는 Imagenet과 같은 큰 데이터셋으로 학습을 시킵니다. 2단계로 그렇게 훈련된 모델을 작은 데이터셋에 적용시키는 것입니다. 원래대로라면 마지막 FC layer는 최종 feature와 class scores간의 연결로 imagenet일땐 FC-1000, 4096 * 1000차원의 행렬이 있었는데 그것을 제거하여 초기화해줍니다. 그리고 나머지 레이어들의 가중치는 freeze시키는겁니다. 그렇게 되면 마지막 레이어만을 가지고 데이터를 학습시키게 되는 것입니다.
Caltech-101의 그래프를 보게 되면 녹색선은 Alexnet을 이용한 것이고, 파란선은 SVM을 이용한 로지스틱회귀로 훈련한 것입니다. 불과 Caltech의 데이터 세트에는 클래스 당 5-10 개의 샘플이 있었다고 합니다.

비단 Caltech에만 해당되는 것이 아니라 기존의 모델들의 앙상블로도 충분히 더 좋은 성능을 이끌어 낼 수 있었습니다.

imagenet에서 사전 학습 된 모델의 기능을 사용한 다음 단순히 선형 학습 다운 스트림 작업에 대한 모델 위에 적용되며 이는 적용되지 않습니다. 이미지 분류에만 적용됩니다. ????

이미지 데이터에 대해 사전 학습 된 모델에서 이러한 기능을 추출하고 그런 다음 간단한 Nearest-Neighbor 절차를 사용하여 이미지 검색 작업을 수행하고 다시 Nearest-Neighbor을 사용하여 이미지에서 이러한 사전 훈련 된 특징 벡터 위에 많은 이미지 세트에서 많은 검색을 하는 방법이 있습니다.

새롭게 만들어진 추출기로 계속 개선하기 위해 모델의 가중치를 계속 업데이트하게 되는데 이 다운 스트림 작업의 성능과 여기에 몇 가지 트릭과 팁이 있다고 합니다.
fine-tuning 전에 특징을 추출한 후 훈련을 해야하고, learning rate는 낮추는것이 좋다고 합니다. 이미 학습이 잘 되어있기때문입니다.
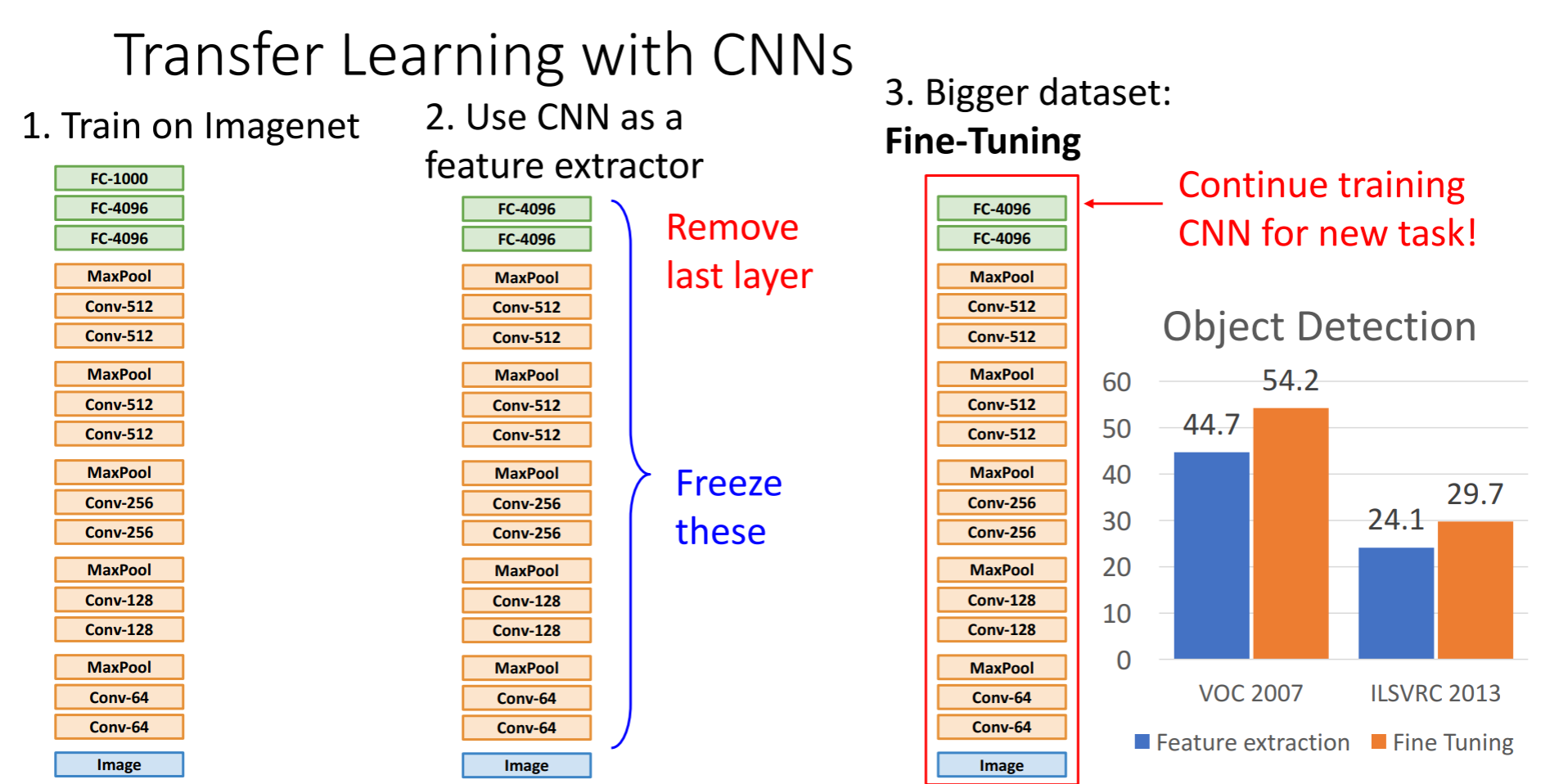
그래프를 통해 Fine-Tuninig이 기존의 Feature extraction보다 나은 것을 확인할 수 있습니다.

Fine tune에 대해 좀 더 알아보겠습니다.
예를 들어 Imagenet에서 학습을 시킬 때 가지고 있는 데이터로 학습을 했는데, 새롭게 학습시킬 데이터셋에도 같은 데이터 셋이 있고 그것이 적은 양의 데이터셋이라면 top layer에서 linear classifier를 사용하면 됩니다. 어느 정도 양이 있다면 finetune을 하게 되는 것입니다.
문제는 Imagenet에서 학습을 시켰을 때 없는 데이터라면 다른 stage에서 선형분류기를 쓰든 다른 방법을 생각해보아야 할 것입니다. 데이터를 증가시키는 방법 같은걸로. 그러나 어느정도 데이터가 있다면 이 또한 finetune으로 해결할 수 있다고 합니다.
'풀잎 DeepML' 카테고리의 다른 글
| cs231n lecture8 CNN (0) | 2021.02.15 |
|---|---|
| cs231n lecture 7 Convolutional Networks (3) | 2021.02.07 |
| 1주차 Image Classification (0) | 2021.01.02 |


