
A.I
cs231n lecture 7 Convolutional Networks 본문

컨볼루션 연산을 수행하는 또 다른 유용한 방법으로 리셉티브 필드가 있는데
예시는 input의 3X3 region이 receptive field가 된다는 것입니다.
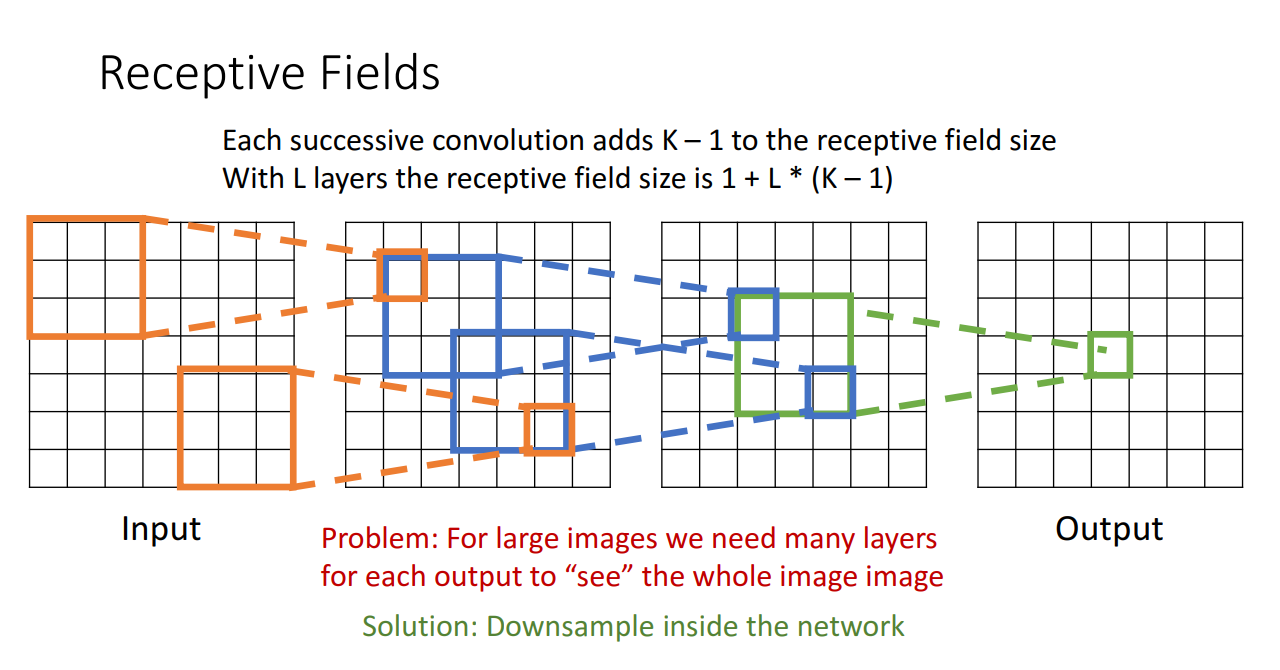
위 예시는 3-conv layers일때의 receptive field 예시입니다. output tensor부터 점점 확장해 나가며 3x3 regin이 5x5 region이 되고 7x7 region이 최종 receptive fild size가 됩니다. 이러한 receptive field size를 1+L*(K-1)으로 계산할 수 있습니다.
하지만 input image의 해상도가 커질수록 그만큼 conv layer가 많아지며 (kernel size가 위와같이 3일경우엔 500개 가량의 convlayer가 필요) output에서 각 spatial position이 매우 큰 receptive field size를 커버한다는 뜻이므로 좋지 않은 형태라고 할 수 있습니다.
이 점을 이용하여 이미지와 같은 고차원 입력을 처리 할 때는 너무 많은 컨볼루션 레이어가 필요하기때문에 이전 볼륨의 모든 뉴런에 뉴런을 연결하는 것은 비현실적임을 감안해 네트워크에서 다운샘플링을 통해 레이어의 각 뉴런을 input 레이어의 로컬한 영역에 연결하는 것입니다.

Filter가 합성곱을 진행할 때 몇 칸 씩 움직일 지 그 기준을 정하는 값을 바로 stride라고 합니다. 위 그림은 stride가 2인 상황입니다. Input size가 W인경우 Filter의 크키가 K라면 Padding이 P라고 볼 수 있는데 그럴 경우 Output의 크기를 알아 낼 수 있습니다.
Stride 값에 따라 output size는 달라지며, stride 값이 커질수록 output size는 작아진다고 합니다. 그래서 보통 패딩을 통해 0을 집어 넣는다고 합니다.

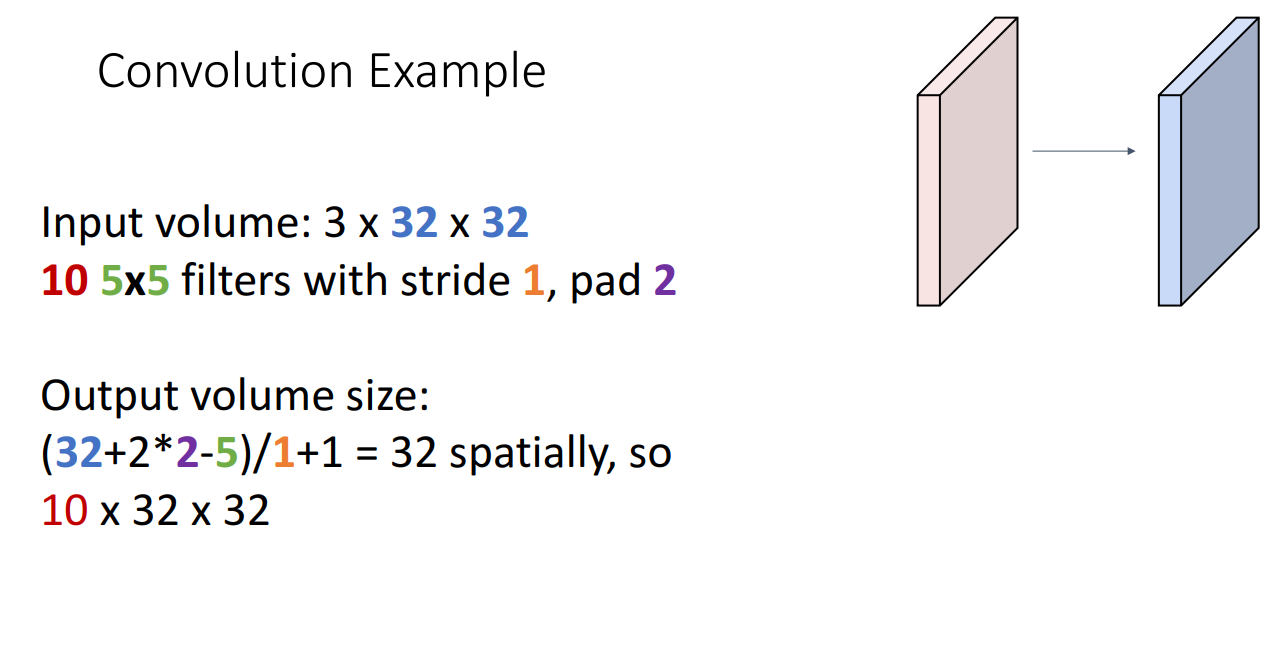
위 슬라이드의 공식을 적용해보면 input size인 32에서 filter size인 5를 빼고 pad가 2 이므로 4를 더 한 값을 stride+1로 나눠주어 32라는 output값이 나왔습니다. 또한 필터가 10개 였으므로 output volume의 크기는 10X32X32가 됩니다

레이어의 파라미터 개수는 어떻게 구할까요? filter 1개가 5x5의 필터사이즈와 input의 뎁스 3을 곱하여 75개의 파라미터를 갖습니다. 거기에 bias term을 고려해야 하므로 76개 입니다. 10개의 filter가 있다면 760개의 파라미터를 갖습니다. 강의에서 763개의 파라미터를 갖는다고했는데 ...?

Tensor가 10X32X32의 형태를 가지고 있기때문에 두 Tensor 사이의 내적을 구하면 76만8천번의 연산을 해야한다는 것을 알 수 있습니다.
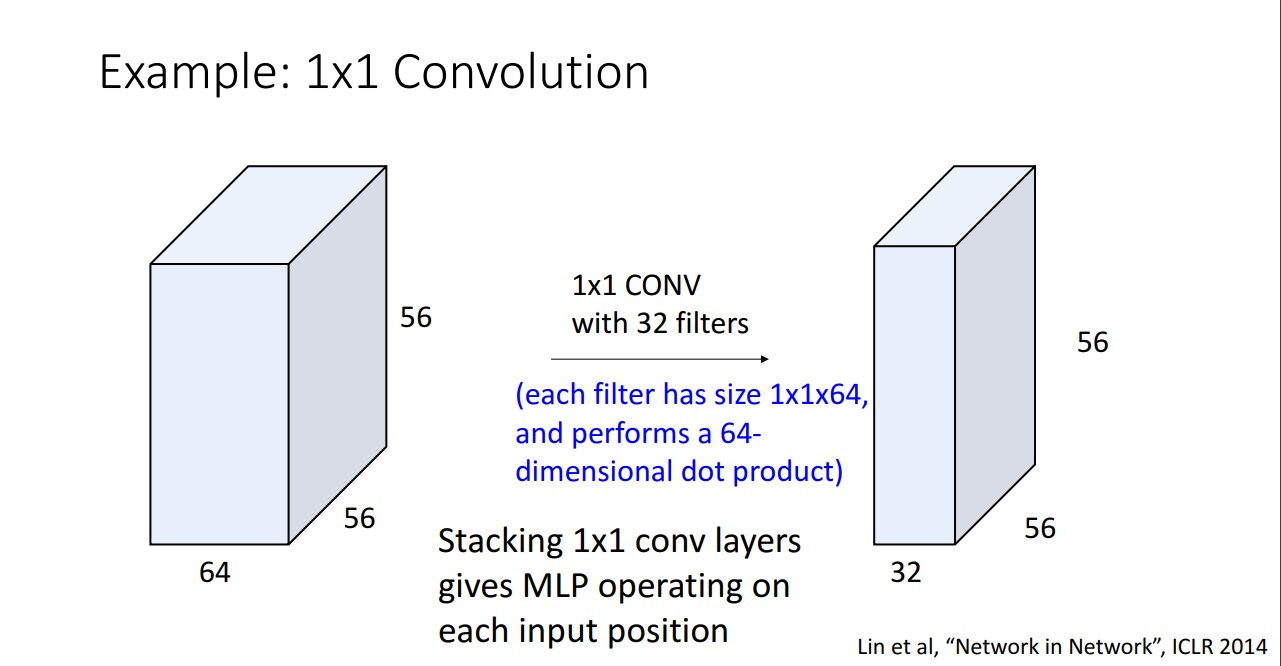
먼저 1*1 Convolution을 사용하면 필터의 개수가 몇 개 인지에 따라 output의 dimension은 달라지지만, 원래 가로 세로의 사이즈는 그대로 유지됩니다. 그래서 filter 의 개수를 원래 input의 dimension 보다 작게 하면, dimension reduction의 효과가 납니다.
Dimension reduction을 이용하기 위해 1*1 conv 의 개수를 줄이면, activation의 depth가 작아져서 filter의 총 parameter의 개수가 감소한다.
이 형태를 bottleneck 구조라고 하는데, dimension reduction을 한 뒤 모든 연산을 하고 다시 filter의 갯수를 늘려서 고차원으로 늘리는 방법을 이용하기 때문에 bottleneck이라고 부른다.
- bottleneck 구조에 대한 설명
1x1 convolution layer는 depth 측면에서 input image를 줄일 수 있습니다. 사실, 입력하는 채널의 수와 출력하는 채널의 수가 완전히 동일하다면 convolution의 큰 의미는 없을 것으로 생각됩니다. 하지만 차원의 수를 바꿔준다면 이야기는 달라집니다. input 파라미터 비해 적은 수의 차원으로 차원이 축소된 정보로 연산량을 크게 줄일 수 있다. 한번 이렇게 줄여 놓으면 뒤로가면 연계되는 연산량의 수, 파라미터의 수가 확 줄어들기 때문에 같은 컴퓨팅 자원과 시간 자원으로 더 깊은 네트워크를 설계하고 학습할 수 있게 된다. 그런데, 차원을 단순히/무작정 작게만 만든다고 다 되는 것은 아니다. 적당한 크기가 필요하고, 그 다음의 레이어에서 학습할 만큼은 남겨둔 적당한 차원이어야한다. 이러한 구조를 잘 활용한 것이 bottleneck 이라는 구조이다.


conv layer의 출력값이 작아질수록( Stride 값이 커질수록 ) FC layer(Full Connection layer)에서 필요한 파라미터수가 줄어든다. 이러한 common setting이 있다 정도로 이해했습니다.
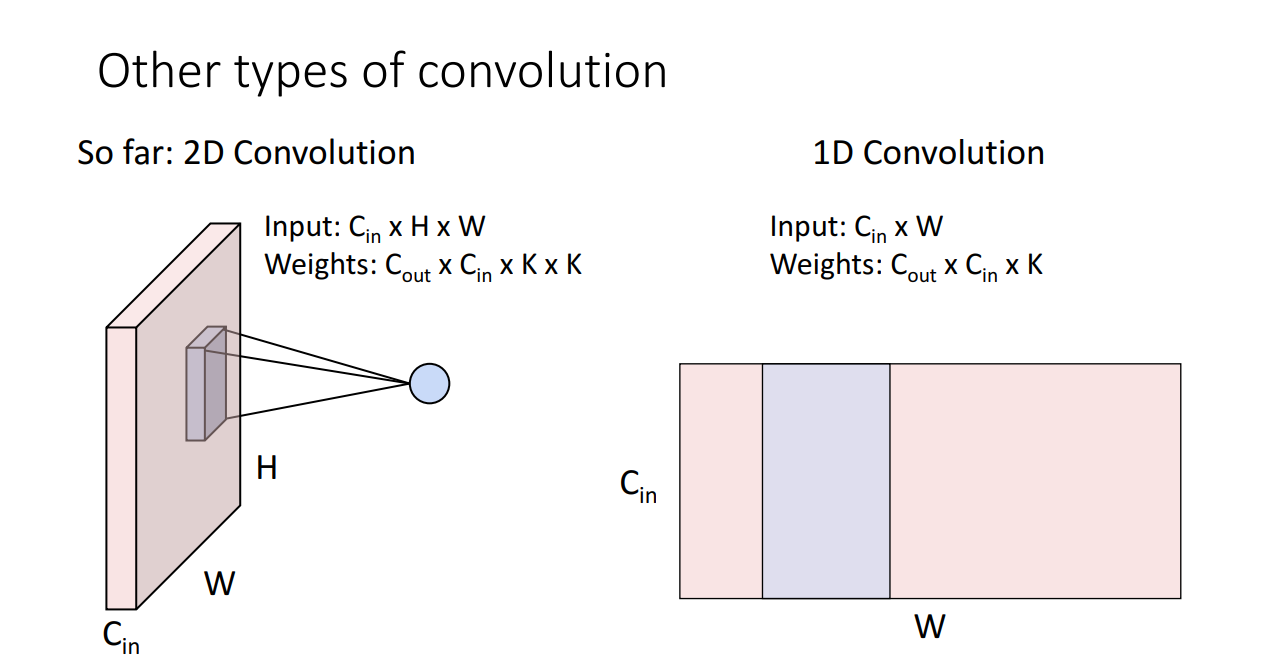
우리가 이제까지 봐온 2D convolution 외에 1차원 컨볼루션의 형태도 볼 수 있는데
- 시계열 센서 데이터 분석.
- 고정 길이 기간 (예 : 오디오 녹음)에 대한 신호 데이터 분석.
- 자연어 처리 (NLP), 장단기 기억 (LSTM) 셀 을 활용하는 반복 신경망 은 학습 가능한 패턴을 생성하기 위해 단어의 근접성을 고려하므로 CNN보다 더 유망합니다
를 처리하는데 더 효과적이라고 합니다.
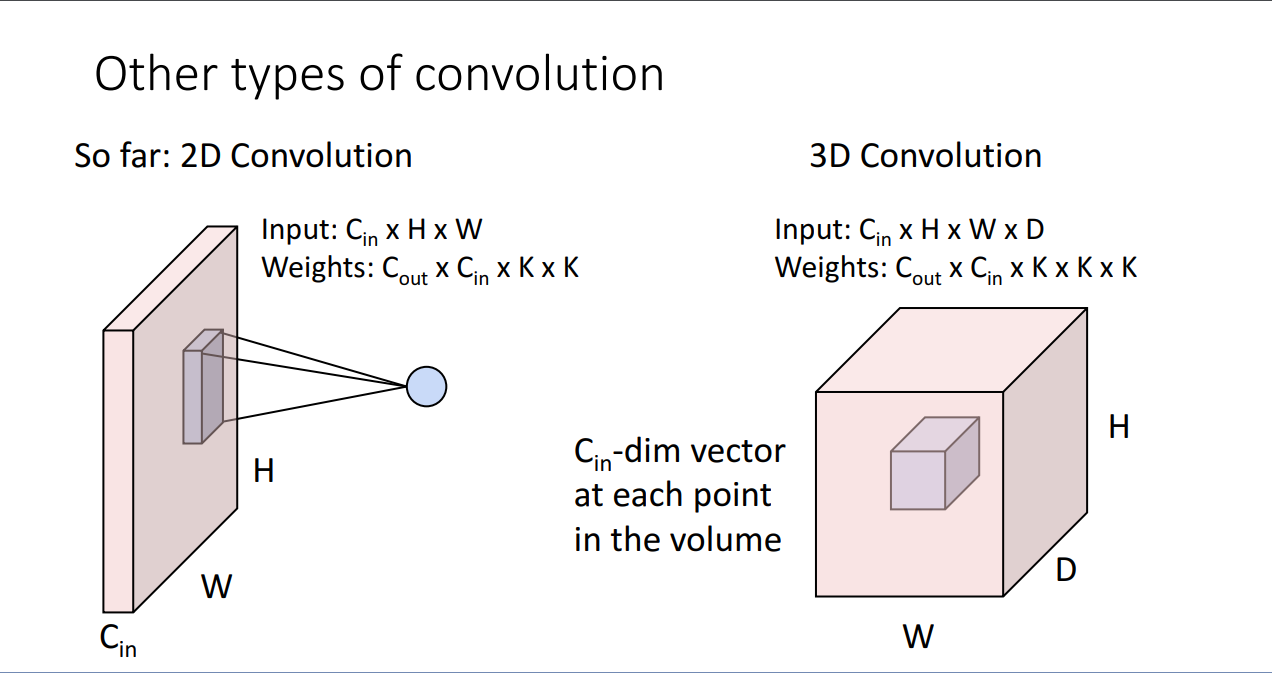
또한 3D 컨볼루션의 형태도 볼 수 있는데 이는 point cloud data 혹은 3d data에 사용에 쓰인다고 합니다.


파이토치에서 이렇게 쓸 수 있다고 합니다
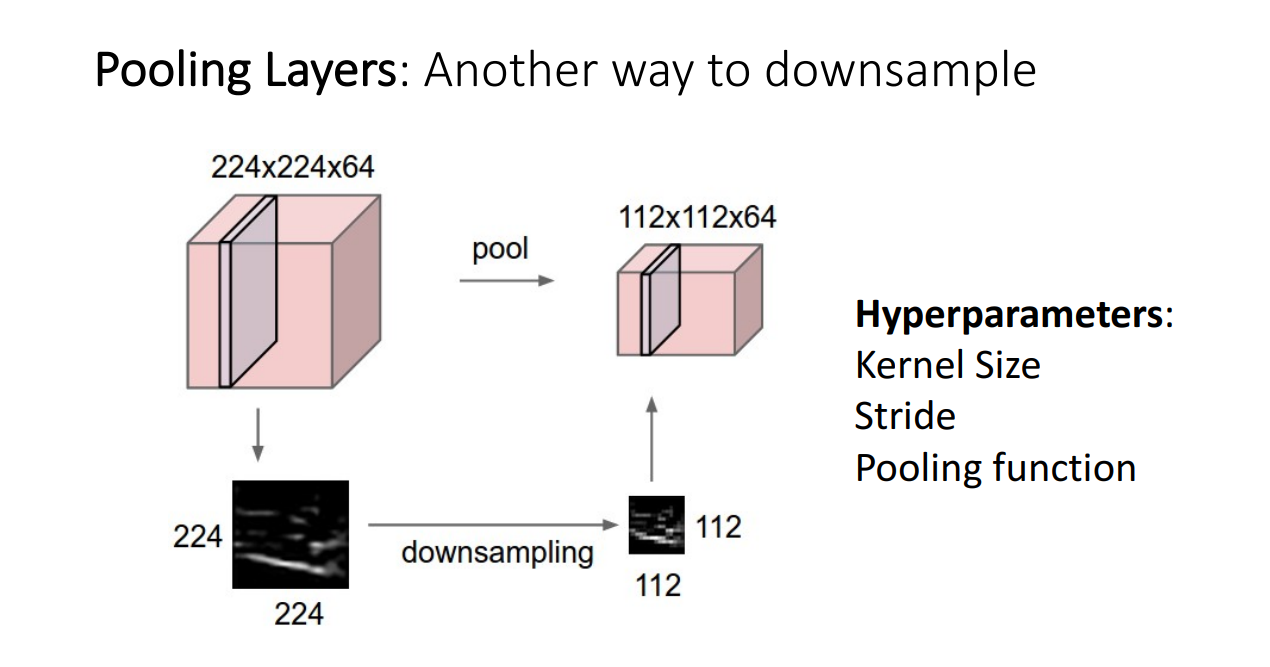
Pooling layer란 추출한 특징은 최대한 유지한 채 이미지의 크기를 줄여주기 위한 장치입니다. 이미지의 크기를 줄이는 이유는 좀 더 다루기 쉽게하기 위함인데 downsampling이라고도 불립니다. 그림을 작은 사이즈로 줄이면, 연산량을 줄일 수 있기때문에 사용합니다.
이전의 conv layer의 stride와의 다른점은 learnable parameter가 없다는 점이다. pooling layer에서는 hyperparameter로 kernel size와 stride, pooling function만 신경쓰면 된다고합니다.
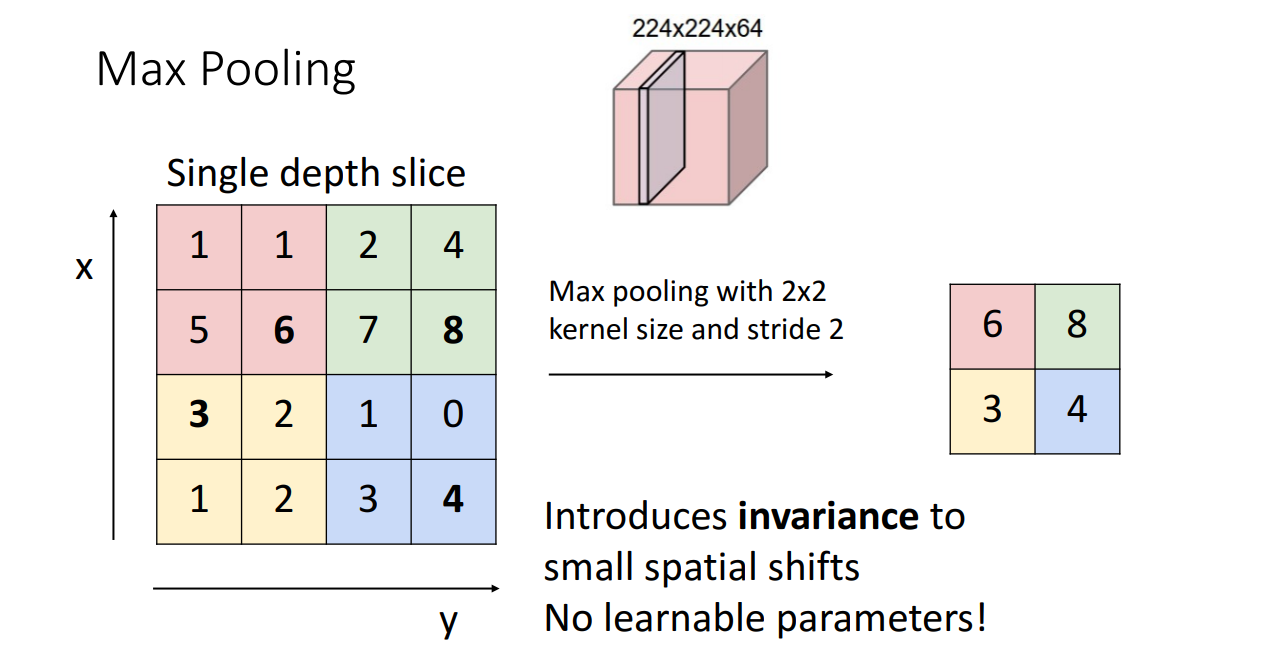
위 예시는 kernel size와 stride가 2인 2x2 max pooling을 하는 모습입니다. kernel size와 stride가 2로 동일한 이유는 pooling region이 overlapping되지 않게 하기 위해서입니다.
stride 2 maxpooling은 2x2 사각형에서 가장 큰 값만을 취합니다. average pooling보다 max pooling이 좋은 이유는 특정 filter에서 fire된 값(높은 값)으로 scoring된 경우 그 정보를 다음 layer로 그대로 가져갈 수 있기 때문이라고 합니다.(값이 크다는 것은 특징을 그만큼 잘 나타내고 있기때문).

이러한 Pooling Summary가 있습니다.
'풀잎 DeepML' 카테고리의 다른 글
| Lecture 11 : Training Neural Networks(Part 2) (0) | 2021.03.01 |
|---|---|
| cs231n lecture8 CNN (0) | 2021.02.15 |
| 1주차 Image Classification (0) | 2021.01.02 |


