
A.I
cs231n lecture8 CNN 본문

구글넷은 매개 변수 감소 개수, 메모리 사용량 개선 및 계산능력 향상을 시키기 위해 많은 혁신을 했다고 합니다.
그 중 첫번째 특징으로 stem network를 사용한 것인데 input을 다운 샘플링하는 Conv로 시작해 이미지의 공간 해상도를 다운 샘플링하기 위해 conv - pool - conv - pool layer의 행태로 만들어졌다고합니다.

그림에서 볼 수 있다시피 VGG-16과 비교해보면 전체 공간 해상도를 기준으로 224개에서 28개까지 다운 샘플링합니다.
그에 따른 메모리, 파라미터 개수, flop 비용등을 보면 VGG-16에 비해 눈에 띄게 줄어든 것을 확인할 수 있습니다.
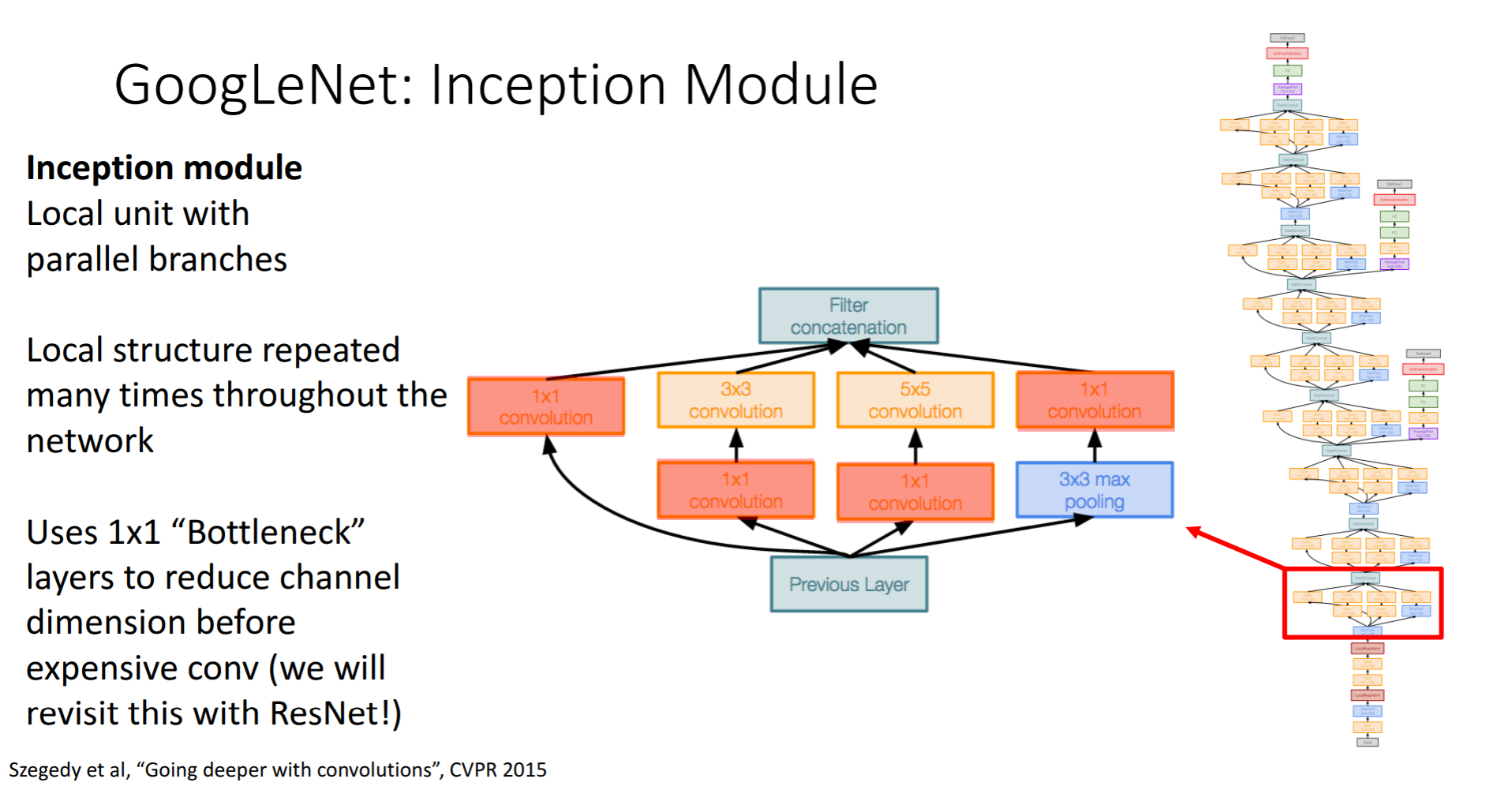
두번째 특징으로 Inception Module을 들 수 있는데 모듈의 끝에 다시 모듈을 쌓아 올리는 방식으로 인공신경망의 구조를 이루게 합니다.
Inception Module에 대한 설명을 순차적으로 하자면
다음은 naive inception module입니다
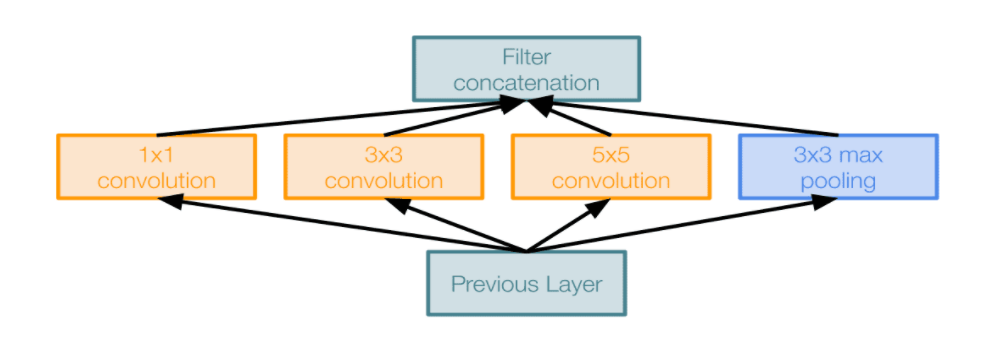
이 그림에서 1*1, 3*3, 5*5 CONV layer 와 3*3 MAX POOL layer 를 평행하게 적용하여 최종적으로 모두 depth를 wise하게 이어붙여 출력을 만들어내는 구조입니다. 이렇게 했을 때의 문제점은 바로 computational cost 가 비싸다는겁니다.

해당 모듈에 28*28*256 의 입력이 들어오게 된다면 위와 같은 CONV layer 를 통과하게 되었을 때 computational cost 가 어떻게 되는지 계산해본다면 1*1*128 CONV layer 를 통과하게 된다면 28*28*128 의 output 이 나오게 되고, 마찬가지로 모두 다 계산해보면 의 output 이 되게 됩니다. 뿐만 아니라 연산량(operations)는 무려,
[1*1 conv, 128] = [3*3 conv, 192] =
[5*5 conv, 96] = 가 되어 최종적으로 854M 만큼이 됩니다
이는 너무 값비싼 연산이 되는데, pooling layer 도 feature 의 depth 를 유지하기 때문에 결국 연쇄작업을 하게 되면 depth 는 매 레이어마다 증가할 수 밖에 없게 됩니다.
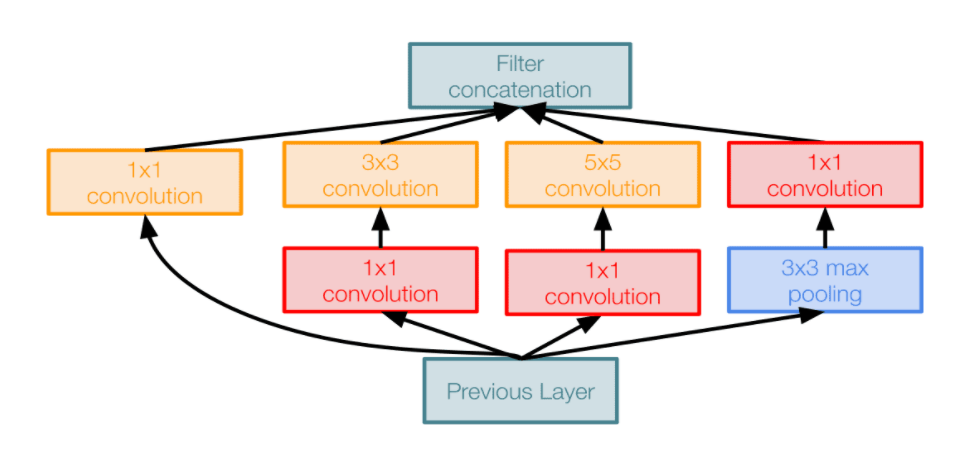
이를 해결하기 위해 bottleneck layer 를 도입하게 됩니다. bottleneck의 특징은 공간은 유지되면서 채널(depth)이 줄어드는 효과를 얻게 되는 것입니다. 이러한 bottleneck layer 를 다음과 같이 적용시키므로써 dimension reduction(차원 축소) 을 진행하는 inception module 은 다음과 같이 아주 많은 계산 상의 이점을 가져오게 합니다.
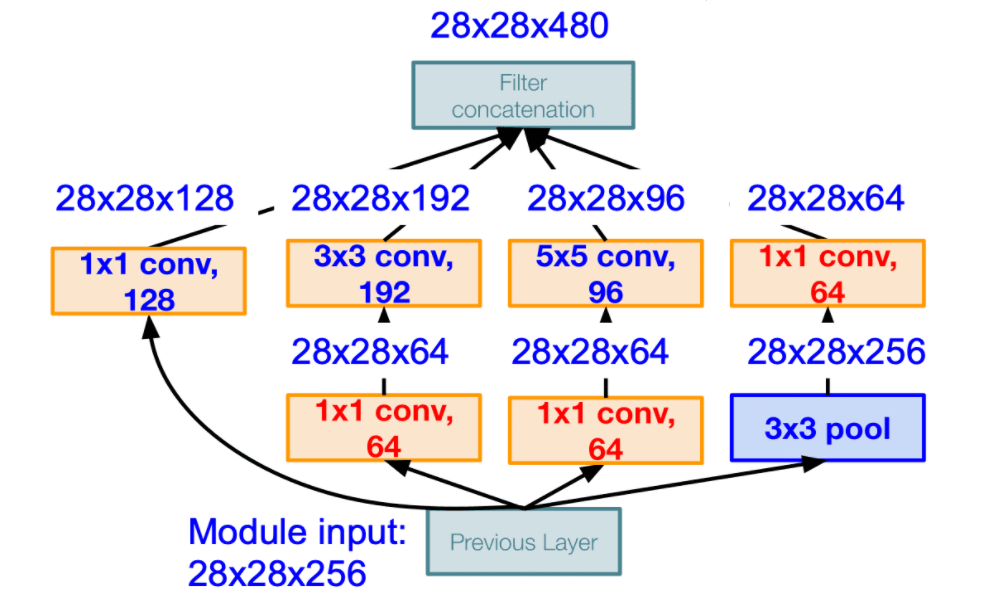
최종적으로 filter concatenation 을 하게 되면 28*28*480 으로 약 2/3 로 줄어들은 것을 확인할 수 있으며, 연산량을 모두 계산하면 358M 이 되어 절반 정도로 줄어들은 것을 볼 수 있습니다. pooling layer 역시 depth 가 낮아지는 것을 확인할 수 있습니다.


세번째로 Global Average Pooling을 쓴다는 것인데 Global Average Pooling의 개념은 모델의 총 매개 변수 수를 줄여 과적합을 최소화하는 것이라고합니다. Max Pooling Layer와 마찬가지로 GAP는 3 차원 텐서의 공간 차원을 줄이는 데 사용됩니다. 그렇게 VGG-16과 비교해볼 때, 마지막에 계산이 많은 FC layer 대신 공간 차원을 축소하고 클래스 점수를 생성하는 하나의 선형 layer가 들어가 있는 것입니다.
참고 : alexisbcook.github.io/2017/global-average-pooling-layers-for-object-localization/

마지막 특징으로 위의 그림처럼 중간중간 튀어나온 layer들이 있는 것을 볼 수 있는데 Auxiliary Classifiers라고 하며 중간 loss를 구하는 지점이라고 할 수 있습니다. Auxiliary Classifiers를 쓰는 이유는 network가 너무 깊기 때문에 중간에 gradient가 사라질 수 있는 가능성을 최소화 하기위해서입니다.
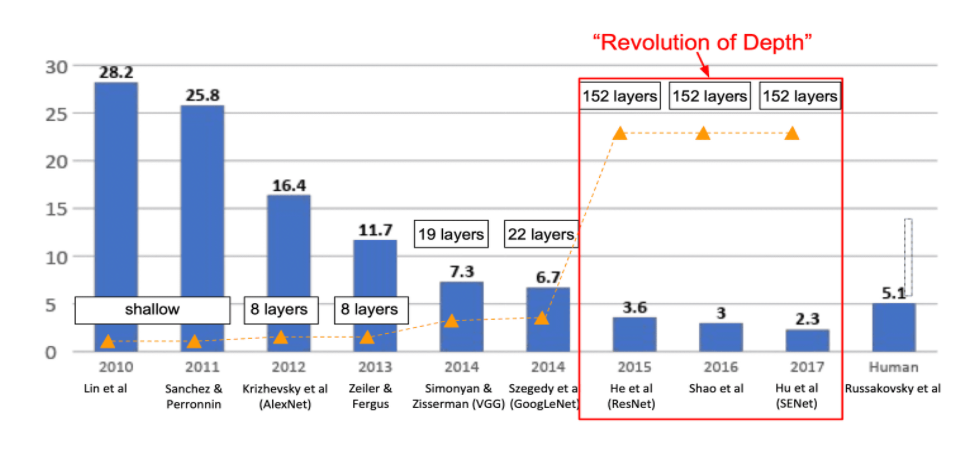
최근까지의 연구성과를 보면 위 그래프와 같다고 합니다.
다음은 Residual Networks 줄여서 ResNet입니다.
먼저 ResNet의 시작점부터 보겠습니다.

일반적으로 신경망의 깊이가 깊어지면 성능이 증가할 것이라고 믿었습니다. 왜냐하면 더 복잡한 정보를 처리할 것이라 생각했기 때문입니다. 위 그림을 보면 56 layer가 20 layer보다 성능이 좋지 않은 것을 볼 수 있습니다. 여기서 추측해보면 일반적으로 Deep model일수록 overfitting이 나올 가능성이 높다고 생각할 수 있습니다.

그러나 training 에서도 에러가 증가하는 것을 보면 전체적인 성능이 낮아지는, underfitting 이 일어나고 있는 것을 볼 수 있습니다.

그래서 한가지 가설을 세워보았다고합니다. 모델이 깊어질수록 최적화하기가 어려워진다는 것입니다. 구조적으로 이를 해결하기 위해서는 shallower layer를 가진 모델의 가중치를 deeper model에 복사를 한다음 추가적인 layer들은 identity mapping(input을 output으로 내보내는 것)을 한다는 것입니다. 그렇게 하면 적어도 shallower model의 성능은 나오지 않겠나 라고 생각한 것입니다.
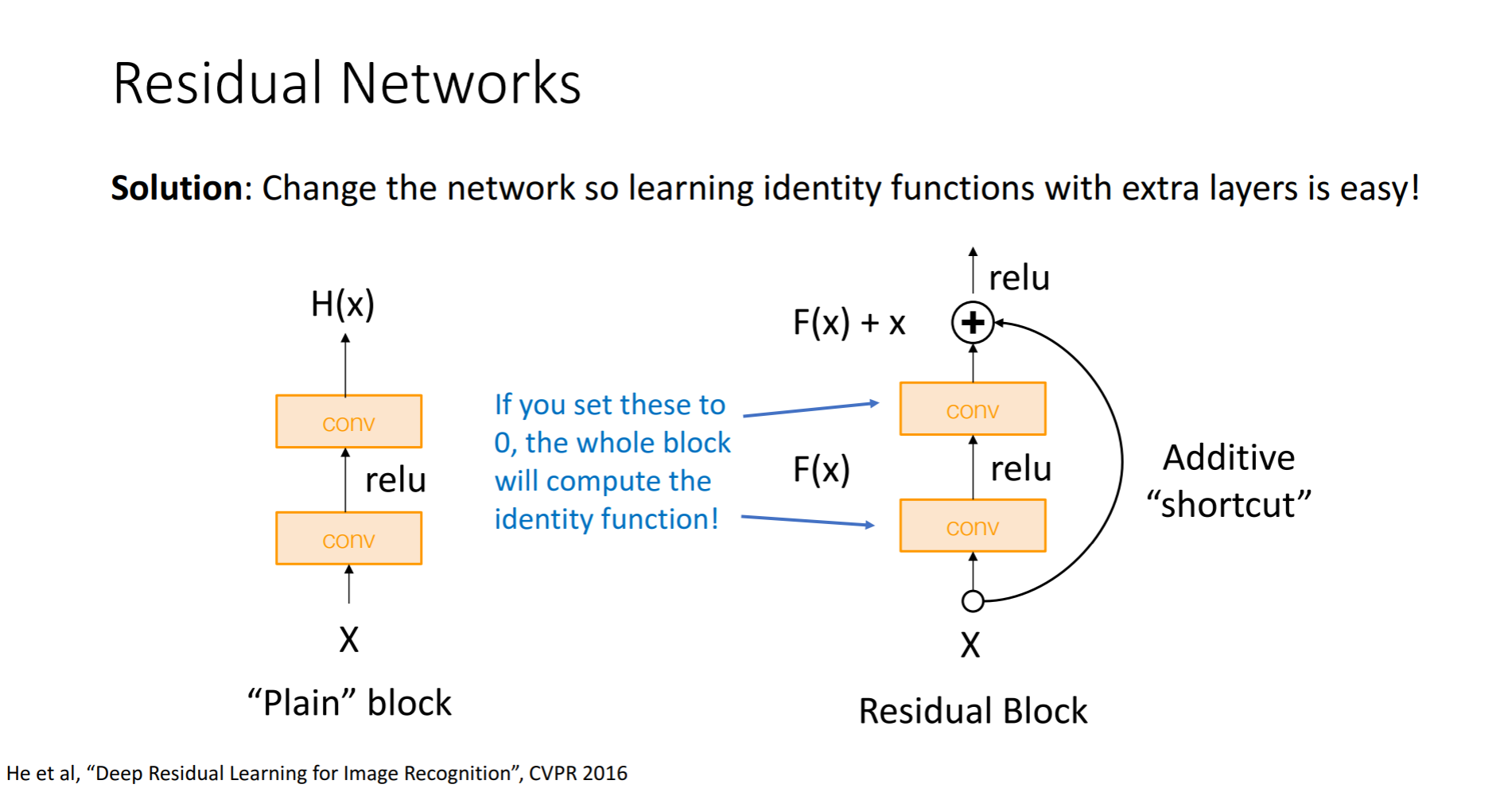
기존의 layer는 출력값 H(x) 를 최적화 하는 방식이었는데, Residual layer에서는 f(x) + x = H(x) 를 학습하게 되는 것입니다. 그래서 입력값 x와 출력값 H(x)의 차이인 f(x)를 최소화하는 것이 목표입니다. 즉, f(x)=0이 되도록 layer를 다르게 설계하게 되는 것입니다. 결과적으로 input과 output이 direct하게 mapping되지 않고, identity를 더한 어떤 잔차를 학습시키는 형태로 네트워크가 진행이 됩니다.

ResNet의 특징으로 5가지 정도를 들 수 있습니다.
- 모든 residual block 은 2개의 3*3 CONV layer 를 갖는다.
- 주기적으로 두 배의 filter 를 주고 stride 2 를 이용해 공간적인 downsampling 을 진행하도록 한다.
- 시작할 때 7*7 CONV layer 를 이용한다.
- 마지막 CONV layer 뒤에 global average pooling layer 로 pooling 을 진행한다.
- FC layer 는 output class 만을 위해 있고 더는 없다(no multiple FC layer).

이러한 버전들이 있다고 합니다.

더 많은 layer를 사용하여, 더 적은 비용을 만들어 내기 위해 bottleneck 구조를 사용한다는 내용 같습니다.
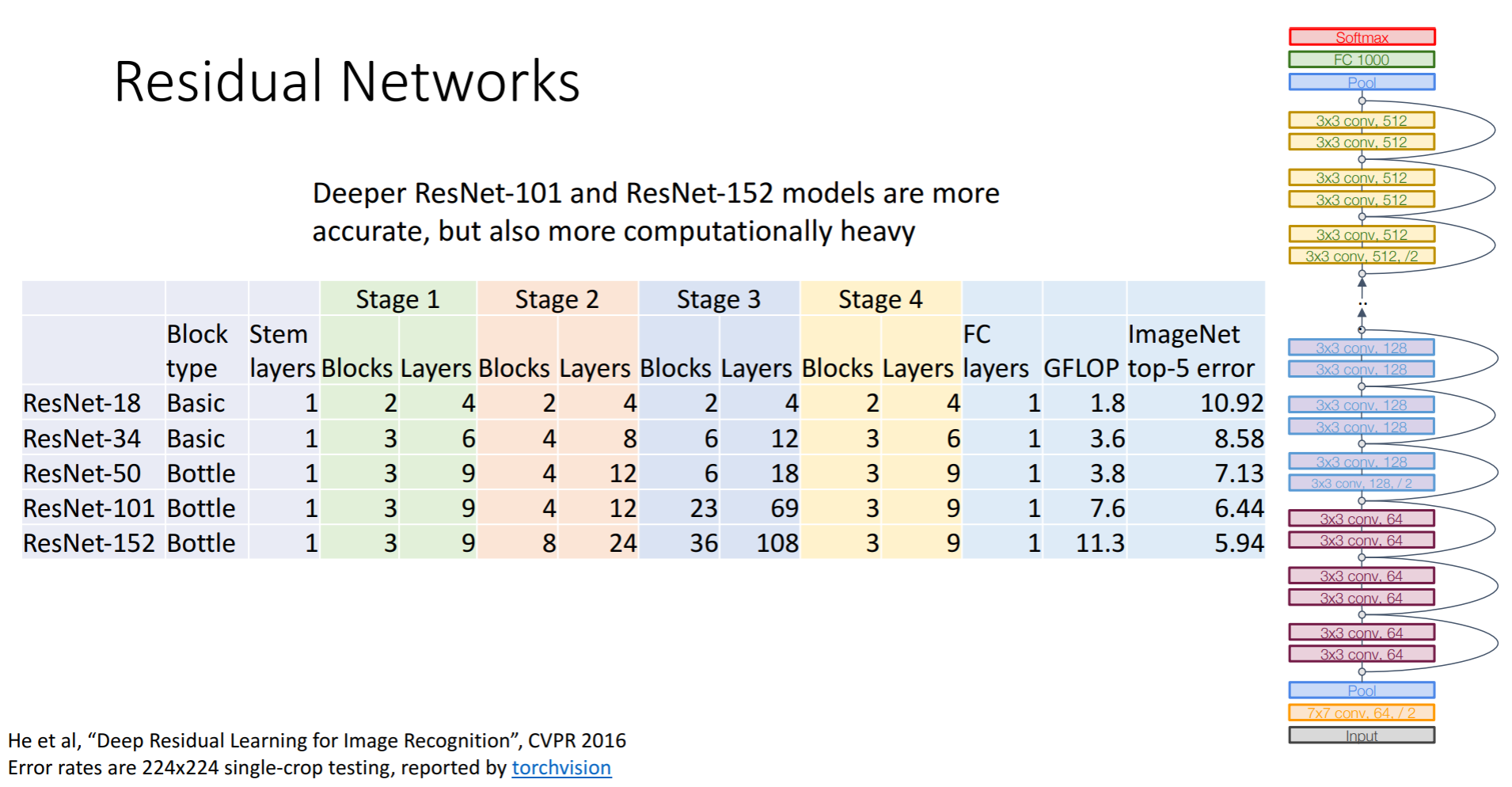
현재 쓰이는 ResNet 구조로는 18, 34, 50, 101, 152의 5가지 구조가 있는데 layer가 50을 넘어가면 보통 bottleneck 구조를 쓴다고 합니다. 50부터는 파라미터가 급격하게 증가하기 때문입니다. 101과 152 모델은 더 정확하지만 무겁다는 단점이 있다고합니다.
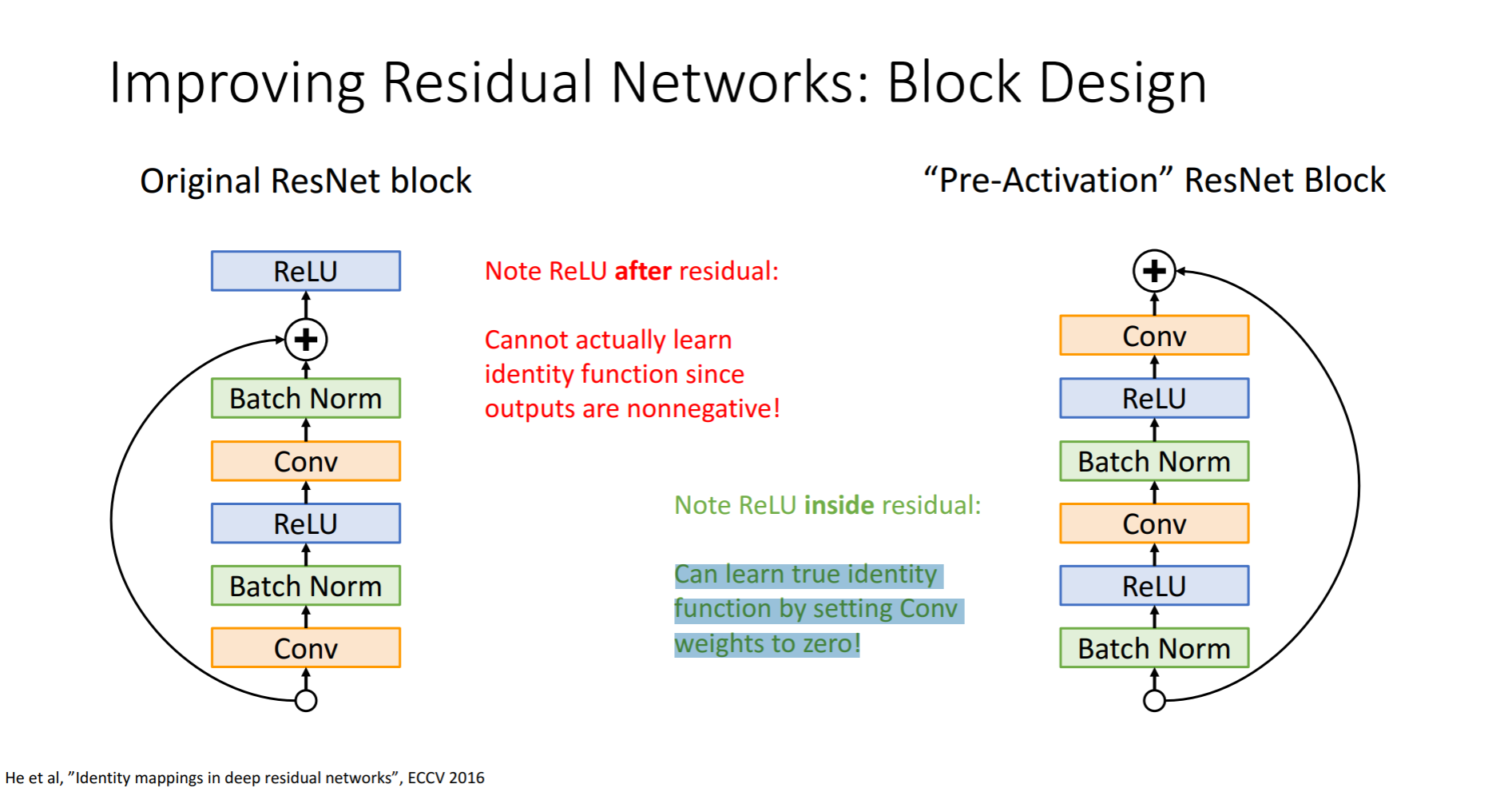
가중치를 0으로 만든 Conv를 거쳐야 indentity function을 학습할수 있다는 뜻인것 같습니다?
'풀잎 DeepML' 카테고리의 다른 글
| Lecture 11 : Training Neural Networks(Part 2) (0) | 2021.03.01 |
|---|---|
| cs231n lecture 7 Convolutional Networks (3) | 2021.02.07 |
| 1주차 Image Classification (0) | 2021.01.02 |


